Data Versioning for Contemporary Data Teams and Systems
Written on
Chapter 1: Understanding Data Versioning
In the realm of databases, data warehouses, and data lakes, both administrators and users encounter a common challenge: the data available to them only reflects the present state of affairs. Given that the world is in a constant state of flux, this data is likewise subject to ongoing changes. Retrieving an older version of data can be cumbersome, often requiring a look through log files, which is not ideal for analytical purposes. Therefore, a practical solution that works in tandem with existing data resources is essential.
Moreover, modern systems are increasingly employing varied data formats and sources, including flat files. Consequently, the need arises for a more holistic solution, which I will delve into later.
Data Versioning: Benefits and Best Practices
Data versioning refers to the method of storing various iterations of data that have been created or modified over time. This approach allows for the preservation of changes made to a file or specific database entries. Importantly, it doesn't merely retain the latest version; it also keeps earlier iterations.
Initially, the original version of a file is stored. When modifications occur, these changes are saved, while the original version remains accessible. This capability is invaluable for users like data engineers, who can revert to a prior version in case of issues with the current one. If a problem arises during data integration, for instance, the user can restore the data to a previous correct state.
Data engineers can enhance the data process with additional versioning features that automatically save different data states. One example of such an approach is employing a data vault.
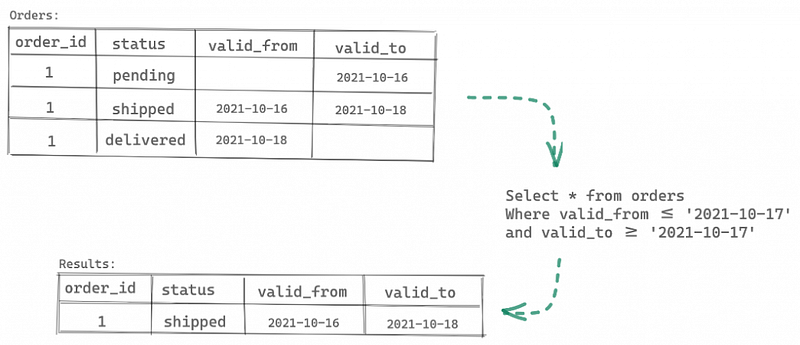
Illustration of Data Versioning in a Data Warehouse Using Data Vault — Image Source: Lakefs
Integrating New Methods like DataOps
Beyond traditional methods of versioning, advanced data versioning can facilitate secure data storage operations. Data scientists may test machine learning models to improve efficiency, leading to modifications in datasets.
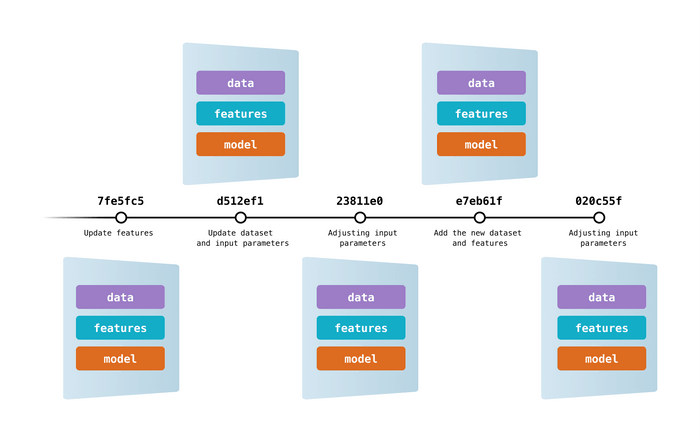
Visual Representation of Data Versioning with Git — Image Source: DVC.org
In this advanced versioning strategy, data and model versions are captured through git commits, providing a means to navigate between different data sets. This unified history of data, code, and machine learning models offers numerous advantages:
- Consistency in project organization through logical naming conventions.
- Flexibility to use various storage solutions for data and models, whether in the cloud or on-premises.
- Enhanced collaboration and distribution of project development among team members.
- Improved compliance with data regulations through auditing capabilities.
- Support for CI/CD-oriented workflows and processes.
Chapter 2: Data Versioning in Modern Data Platforms
As previously noted, architectures like data lakes, warehouses, or lakehouses should incorporate fundamental versioning features to prevent data loss and facilitate versioning throughout data integration and analysis. Moreover, emerging themes such as machine learning and deep learning are being increasingly integrated and managed through DataOps within these platforms.
Utilizing repositories for data and models is advisable, mirroring practices established in traditional software development.
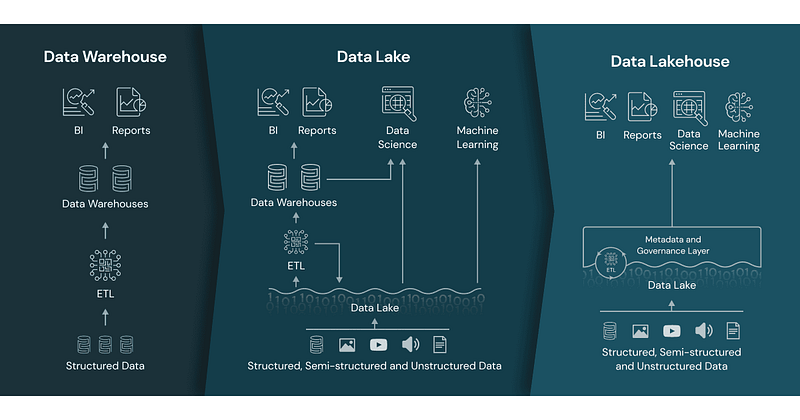
Data Lakehouse Concept Merging Data Lake and Warehouse with Machine Learning — Image Source: Databricks
Implementing Modern Data Versioning
Having established the foundational concepts of data versioning and its relevance to DataOps, let's explore practical implementations. Below is a brief tutorial to help you get started with the open-source solution LakeFS, available for free.
To begin, you'll need an AWS account for S3 storage. Notably, LakeFS provides a convenient CloudFormation template for setup, or you can utilize their demo site without any installation.
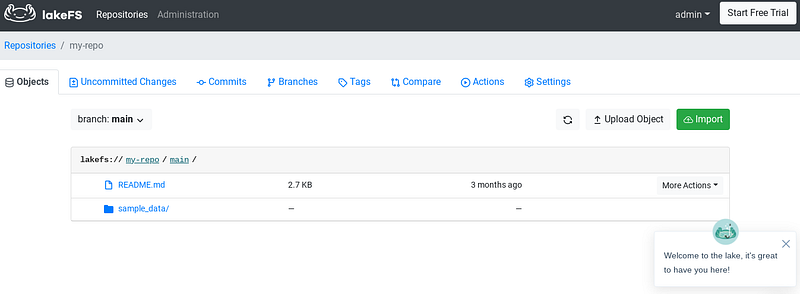
User Interface of LakeFS — Image Source: Own Picture
As a practical example, I uploaded a small CSV file containing some dummy data:
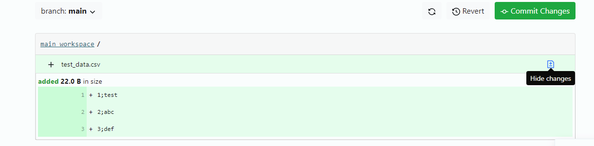
First Data Upload — Image Source: Own Picture
Now, let's assume the data has been modified and the file has been updated (I added an additional row):

Second Upload and Commit — Image Source: Own Picture
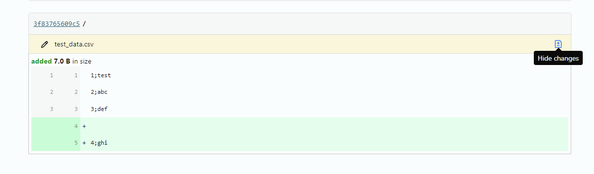
Viewing Updates in the File — Image Source: Own Picture
This example, while straightforward, effectively illustrates the essence of the tool—a source management system akin to GitHub but tailored for data. The data can originate from various sources and be of any size. You can also upload the source code of your machine learning models and manage them similarly.
Next, let's delve deeper by utilizing the AWS CLI. Follow this tutorial to set it up and get started. After configuring the AWS CLI with:
aws configure set --profile lakefs aws_access_key_id YOURID
aws configure set --profile lakefs aws_secret_access_key YOURKEY
You can now list your repositories:
Output:
2022–07–10 18:14:58 my-repo
2022–07–10 18:15:50 test
Next, we'll explore an example that could arise in daily operations, particularly in emergencies. We'll use LakeFS’s default CLI client, lakectl. Install the latest version of the CLI binary on your local machine. Let’s examine the rollback feature. Below are the commits in our repository:
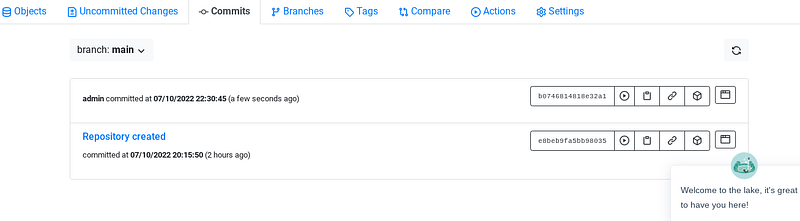
Commits in Repository — Image Source: Own Picture
A rollback operation can swiftly rectify critical data errors. In such scenarios, having robust versioning and rollback capabilities can be invaluable for your team. Use the following command to revert:
lakectl branch revert lakefs://yourURI
This highlights the potential of these tools.
Summary of Key Points
Data versioning is vital for organizations as it allows for the visibility of historical changes within datasets. This capability enables data engineers and scientists to understand data alterations better and resolve issues by reverting to earlier states.
Additionally, data versioning provides users with several benefits, including enhanced collaboration among team members and improved data compliance. The data versioning process is straightforward, as demonstrated in the previous examples.
Sources and Further Readings
Why Your Data Team Needs Version Control - YouTube
This video discusses the importance of version control for data teams and how it enhances collaboration and data integrity.
Data Versioning at Scale: Chaos and Chaos Management - YouTube
This video explores the challenges and strategies of managing data versioning at scale, emphasizing the need for organized workflows.