Claude 2.1 Released: Key Insights and Comparisons with GPT-4 Turbo
Written on
Chapter 1: Introduction to Claude 2.1
On November 21, 2023, Anthropic unveiled its latest Large Language Model, Claude 2.1. In an effort to assess its competitive edge against the leading model, GPT-4 Turbo, I delved into various analyses to gather public opinion on this new release. Below are the key takeaways you should be aware of!

Chapter 2: Contextual Capabilities
From Anthropic's standpoint, the primary distinction between Claude 2.1 and GPT-4 Turbo lies in their context length. The newly launched Claude model features an impressive 200k token context window, enabling it to handle up to 150,000 words or approximately 500 pages of text. This is quite significant!
According to information on Anthropic’s official website, the 2.1 version shows marked improvements over its predecessor, Claude 2.0, particularly in long-context question answering. This enhancement is evident for both 70k and 195k context-length documents.

Chapter 3: Error Rate Reduction
The new model has achieved a reduction in the error rate for long-context question answering by over 30%, indicating a significant leap in performance. However, to form a complete judgment, we must compare the accuracy of Claude 2.1 with the current state-of-the-art model, GPT-4 Turbo. Let’s explore this further!
Section 3.1: Comparison with GPT-4 Turbo
GPT-4 Turbo has a context window of only 128k tokens, which is 64% smaller than Claude’s 200k token window. This gives Anthropic an edge in this aspect!
So how does the accuracy of long-context information retrieval measure up? Greg Kamradt conducted two insightful experiments to evaluate retrieval accuracy as context length increases. Using a consistent methodology for both GPT-4 Turbo and Claude 2.1, comparisons were straightforward. You can refer to the sources for full details; here’s a synthesis of the most critical findings.
Subsection 3.1.1: Experiment Methodology
The experiments followed a standardized five-step protocol: Paul Graham’s essays served as the foundation, with 218 essays offering up to 200K tokens of contextual data. A random fact was inserted at various points within the text. For example: “The best thing to do in San Francisco is eat a sandwich and sit in Dolores Park on a sunny day.” Both GPT-4 and Claude 2.1 were tasked with responding based solely on the provided context. Evaluations were conducted using a GPT-4 instance, employing LangChainAI’s assessment techniques. This process was repeated 15 times, varying the fact's position from the start (0%) to the end (100%) of the document, and across 15 different context lengths ranging from 1K to 200K tokens.
This extensive testing came with a hefty price tag of over $1000, so kudos to Greg for his dedication!
Section 3.2: Results Overview
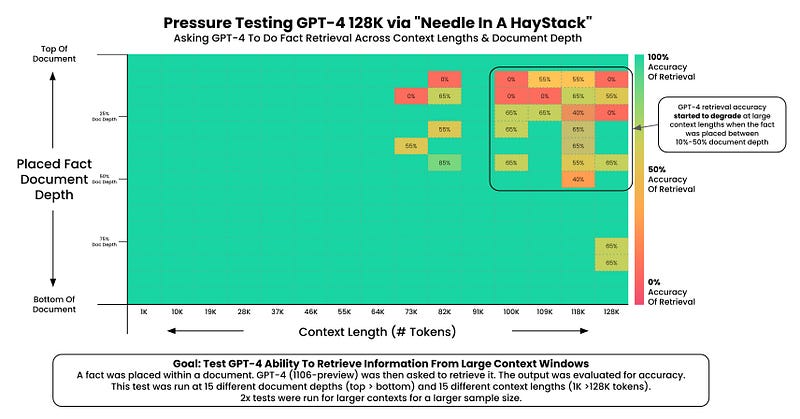
Results for GPT-4 Turbo (128k context window):
Results for Claude 2.1 (200k context window):

Here are some overarching conclusions for both models:
- No Guarantees — Facts are not guaranteed to be retrieved; do not assume they will be in your applications.
- Less Context = More Accuracy — It's advisable to minimize the amount of context provided to enhance recall capabilities.
- Position Matters — Facts placed near the beginning or latter half of the document are generally recalled more effectively.
When comparing Claude 2.1 to GPT-4 Turbo:
GPT-4 Turbo excels in accuracy with information retrieval up to a 64k token context window. Unfortunately, Claude 2.1 shows inconsistencies and performance issues beyond a 24k token context window, with significant drops in effectiveness for contexts exceeding 90k tokens.
Chapter 4: Conclusion
In conclusion, while Claude 2.1 boasts a larger context window, its real-world performance in information retrieval reveals notable instability, particularly with extended contexts. Conversely, GPT-4 Turbo demonstrates exceptional accuracy and reliability in managing contexts up to 64k tokens. For applications requiring consistent and accurate information retrieval within moderate context sizes, GPT-4 Turbo stands out as the more reliable option. However, Claude's extensive context window may still be advantageous in scenarios where large volumes of context are necessary, despite the potential trade-offs in stability and accuracy.
If you're interested in creating custom GPTs and would like a detailed guide—from data collection to API integration—please feel free to reach out to me on X. I’m eager to share my insights and experiences in this fascinating field!
Thank you for being a part of the In Plain English community! Before you leave, don’t forget to clap and follow the writer. Learn how you can also contribute to In Plain English! Follow us on: X | LinkedIn | YouTube | Discord | Newsletter. Check out our other platforms: Stackademic | CoFeed | Venture.